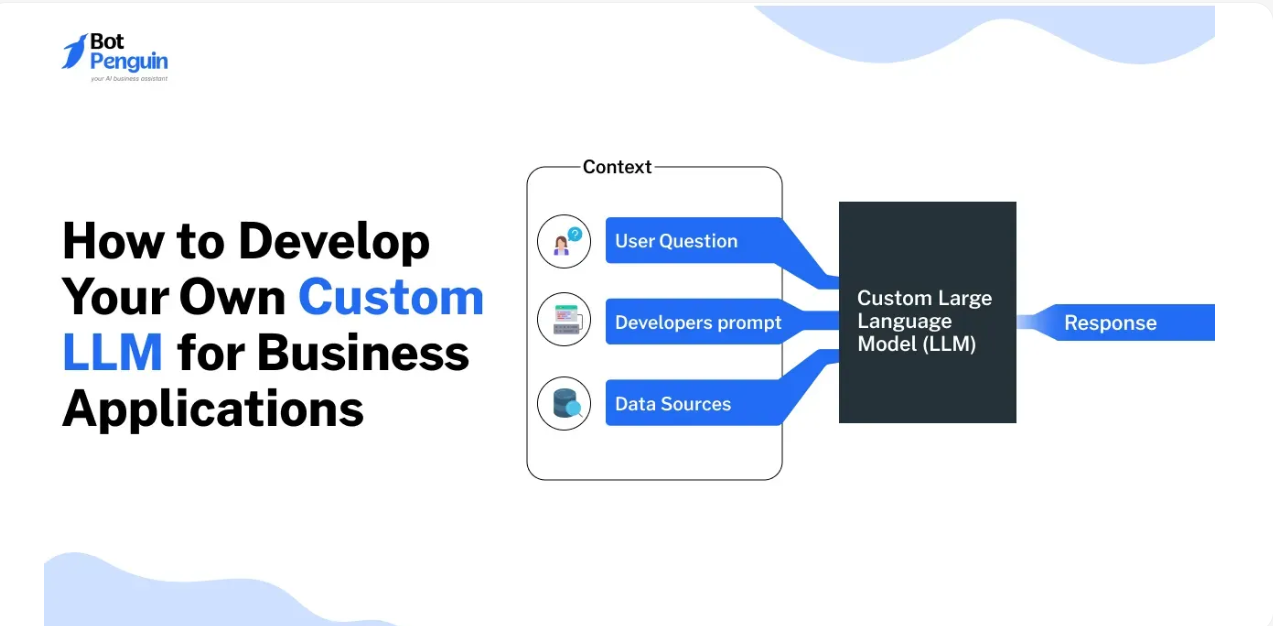
The AI explosion in recent years has made pre-trained language models like GPT-4 a household name. But off-the-shelf models don’t always align with your niche, brand, or data. That’s where custom LLMs come in—fine-tuned models designed around your domain’s jargon, tone, and context. In this post, we’ll dive into why building a custom LLM matters, the step-by-step process, key pitfalls to watch for, and real-world examples that show how to get it right.
1. Why Custom LLMs Matter
While foundation models deliver impressive general performance, they stumble on domain-specific knowledge—whether you’re focused on healthcare, legal tech, or finance. Here’s why going custom is worth it:
Specialized Knowledge: A legal-firm language model grasps case precedents; an e-commerce chatbot knows your product lineup.
Tone & Voice: Brand-aligned dialogue—friendly, formal, or humorous—makes for a consistent user experience.
Reduced Hallucinations: Custom models have fewer errors when referencing domain-specific facts.
Compliance & Privacy: Fine-tuning on your protected data keeps it closer to your servers and processes.
2. Data Collection & Preparation
Success starts with good data:
Gather: Pull in domain documents like manuals, support tickets, transcripts, blog posts, product specs.
Clean: Remove duplicates, broken formatting, and irrelevant text (personal info, ads).
Annotate (optional): Tag with metadata—topic, intent, difficulty level—to guide the model.
Split: Divide the data into training, validation, and test sets to monitor overfitting.
Aim for tens to hundreds of megabytes of high-quality text (a million tokens = ~2MB). It’s not about volume—it’s about relevance.
3. Choosing the Right Method
Three main approaches:
Finetuning: Continue training a base model (e.g., LLaMA, GPT-J) on your data—gains in performance, but costs and setup complexity increase.
Retrieval-Augmented Generation (RAG): Leverage a lightweight model that dynamically fetches facts from an external knowledge base—great balance for factual accuracy.
Prompt Engineering & Adapters: Add adapters or prompt templates—cheaper and faster, but limited customization.
Pro tip: Start with a lightweight open-source model. Evaluate all three methods before committing.
4. Training, Evaluation & Iteration
Train: Use frameworks like Hugging Face Transformers and accelerate on GPUs or TPUs. Monitor loss, perplexity, and model size.
Evaluate: Use domain-specific benchmarks:
Accuracy on FAQs or multiple choice
Human ratings on generative outputs
Generic LLM metrics like F1, BLEU, ROUGE
Iterate:
Diagnose errors—are outputs outdated, overly verbose, ungrammatical?
Tune hyperparameters like learning rate and batch size.
Add curated counterexamples and “negative” samples.
Optionally retrain from scratch using improved data.
5. Deployment & Maintenance
Even after fine-tuning, your work isn’t done:
Deployment: Use managed inference tools (Hugging Face Inference API, AWS Bedrock, OpenAI Fine-tuning endpoints) or self-host via Docker, Triton, or FastAPI.
Monitoring: Track metrics like user satisfaction, hallucination rate, latency.
Feedback loop: Continuously pull new user queries to refine and expand your model’s abilities.
Governance & Ethics: Implement guardrails to watch for bias or unsafe outputs. Regular audits are crucial if served to sensitive industries.
Conclusion
Custom LLMs unlock better relevance, tone, and trust in niche applications—but success hinges on good data, thoughtful method selection, and sustainable maintenance. Start small with RAG or prompt tuning, then scale to fine-tuning once you’ve proven ROI. Above all, keep iterating with fresh data and user feedback.


